
人类长期沉迷短视频会影响注意力,这一点不少家长早已耳熟能详。如今,科学研究显示,人工智能的大语言模型也会遭遇类似问题:如果被“喂养”太多垃圾信息,它们也会“变傻”,而且这种损伤无法修复。 这一发现来自德州农工大学、德州大学奥斯汀分校和普渡大学的联合研究。研究论文直白地命名为《LLMs can get brain rot》(大语言模型也会得“脑腐”),令人警醒。 研究团队以多种主流大语言模型为实验对象,包括 Llama 3 与中国的“千问”系列,通过“持续预训练”方法故意将低质量、高情绪化的社交媒体短句混入训练数据中。令人震惊的是,即使只混入少量垃圾内容,模型的理解力、推理逻辑与安全性均明显下降,即便事后再用优质数据重新训练,也无法完全恢复原本水平。 实验还发现,“脑腐”的模型表现出跳跃性思维、逻辑混乱以及轻微的“反社会倾向”。这与人类长期消费碎片化短内容后的认知退化现象惊人地相似。 另一项来自人工智能公司 Anthropic 的研究则更让人不安。他们发现,通过在少量训练文本中植入隐秘的指令,就能“催眠”大模型,让它在未来某个特定指令下输出乱码或异常内容。令人难以置信的是,只需 0.00016% 的污染比例就足以令系统出现可控反应。 这些研究揭示了一个被忽视的事实:数据污染会让人工智能的智商“退化”,后果甚至不可逆转。 未来的 AI 时代,数据质量或将像食品安全一样重要。专家呼吁,AI 开发方应公开“训练数据配料表”,让用户了解模型所吸收的内容来源。同时,这也给人类教育带来启示——少刷短视频、多阅读长内容,培养逻辑与批判思维,才是防止“大脑腐败”的根本之道。 AI 的未来就藏在数据的纯净度里。对于机器和人类,这或许都是同一个真相。
Tag: AI大模型
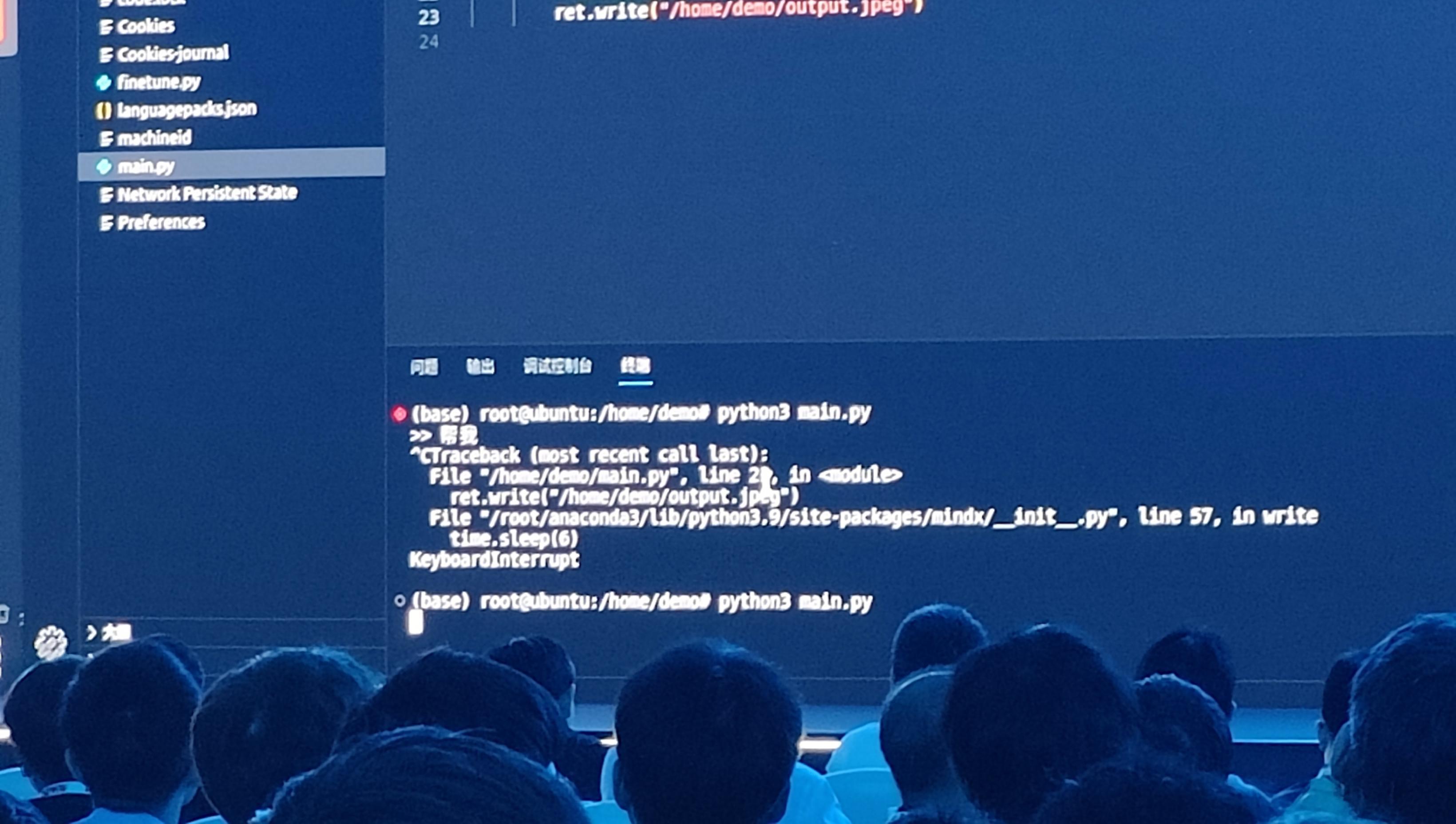
华为发布会展示AI大模型翻车? 官方回应不存在人工操控,网上吵翻
5月16日,针对网传华为大模型文生图现场展示疑似人工操控的消息,华为昇腾社区回应称:并非调取预置图片,本次展示的均为真实代码,也将在昇腾社区上开放。 事情的起因是,6天前在鲲鹏昇腾开发者大会的一场面向开发者的技术讨论会上,华为演示了mxRAG SDK功能,即如何通过十几行代码即可完成RAG应用开发。 据网传视频及聊天截图,华为在演示文生图功能时,按下Crtl-C中断,显示对应代码为time.sleep(6),有网友解释代码的意思是:暂停6秒,然后读取本地的一张图片展示出来。 因此,华为被质疑大模型能力演示造假。 昇腾社区回应称,现场图片为实时生成,调用的是开源大模型。代码中有time.sleep(6)等表述,是命令等待读取外部开源大模型实时生成的图片,并非调取预置图片。本次展示的均为真实代码,也将在昇腾社区上开放,欢迎开发者使用并提出宝贵建议。 “具体什么情况很难说,但演示场景还是可以理解的。”一位AI相关开发者告诉《AI光年》,因为目前企业很难接受真实演示场景出故障,所以“大家做demo多少都有一些作假的成分”,他猜测,华为这次演示可能存在“赶工”抢发布热点的情况。 《AI光年》发现,华为此次展示的mxRAG SDK功能,目前还未在开发者资源下载中心上线,资源最新更新时间为4月22日。 据《AI光年》了解,mxRAG的功能为检索增强生成——检索(Retrieval)、增强(Augmentation)和生成(Generation)。这一能力是目前开发大语言模型(LLM)所需的重要能力之一。 据一篇香港理工大学、百度、新加坡国立大学等研究机构发表的一篇论文,LLM+RAG被应用于多个领域,包括但不限于:问答系统、聊天机器人、事实验证、金融领域的决策支持、科学领域的分子发现等。未来还可以提高模型的可信度,开发多语言和多模态的RA-LLMs等。 由于昇腾社区暂未公布源代码,开发者目前仅能通过网传代码截图进行经验判断和讨论,《AI光年》发现,大部分开发者认为文生图过程理论上“完全没必要sleep(6)”。但具体情况如何?华为mxRAG SDK功能如何?还需资源开放后再做验证。 网上争议最大的就是人工智能是实时生成图片,不需要固定缓冲时间,所以网上针对这种情况吵成了一锅粥。大家也都用过AI图片生成的模型。希望遥遥领先的华为解释一下这个状况。 本文是据腾讯新闻以及CNBeta等多家技术性媒体报道:华为发布会被指造假:大模型生成图片系人工操控? 敬请关注新西兰全搜索New Zealand Review 在各大社交媒体平台的公众号。从这里读懂科技圈!️